How We Gave an AI Agent a Sense of Place: Perceptual Hashing for Autonomous Agent Visual Memory

One of the first things you notice when you build an agent with vision is that, although LLMs are remarkably good at reasoning through complex text, the moment you give them a visual environment to navigate, things suddenly get a lot trickier for the agent to understand. It manifests in different ways, but to make this concrete, let's assume you're working on a harness for an agent to play retro games. You finally hook up some viable tool calling mechanism to your favorite visual LLM, and off your agent goes! Except - it walks into a wall. Then another. You fix the prompt. It walks into the same wall. You add more context. It walks into the wall again, this time with more confidence. The agent isn't stupid - it just has no memory of where it is or what it has already tried, and it may not understand the environment nearly as adeptly as it understands tokens of text. Every wall is, essentially, a new wall - a new challenge to conquer that may as well be a new mountain to climb.
We ran into this exact problem building our own internal research harness for testing autonomous agents in visual environments. The agent needed to make hundreds of sequential decisions, navigate spaces it had never seen before, and - critically - not keep doing things it already knew didn't work. Giving it a genuine sense of place turned out to be one of the most important things we did. And the techniques involved are a lot simpler than I expected going in.
The coordinate trap
The obvious first move is to track position with coordinates. In a retro game context this is tempting - many classic games store the player's map position in memory somewhere, and if you can read it, you know exactly where the agent is. Done!
Except it isn't done, because that approach requires you to instrument each game individually. You need to find where position data lives for every new game you want to support, and that work has to be repeated from scratch each time. It's also more brittle than it looks - two completely different rooms can share the same coordinates across different maps, coordinates don't tell you anything about what the agent can actually do from a given position, and the moment you want to apply the same system to a different type of visual environment (a robot, a web browser, anything else), you're back to square one.
We needed something that works from raw visual input alone - just the screenshot, nothing else - and produces a stable, comparable representation of "what this place looks like." That turned out to be perceptual hashing, which I'll admit I initially dismissed as seeming a bit too simple to actually work that well in practice.
Perceptual hashing: a visual fingerprint
Perceptual hashing has been around since the early 2000s - it's a well-established technique used in reverse image search, duplicate detection, and content identification systems. The core idea is simple: compute a compact numerical fingerprint of an image in a way that makes visually similar images produce similar hashes. This is the opposite of a cryptographic hash - SHA-256 a screenshot, change one pixel, and you get a completely different output. A perceptual hash is designed to change only slightly in the case of minor variations. Two frames of the same room in a game, captured a few seconds apart with a blinking cursor or a character animation mid-cycle, should produce hashes that are pretty close to each other.
The algorithm we use is called average hash (aHash). It is nice and simple:
- Resize the frame down to an 8×8 grid - 64 pixels total
- Convert each pixel to grayscale
- Calculate the mean grayscale value across all 64 pixels
- For each pixel, set a bit to
1if it is brighter than the mean,0if darker - The result is a 64-bit integer

from PIL import Image
def average_hash(image: Image.Image) -> int:
small = image.resize((8, 8)).convert("L") # grayscale 8x8
pixels = list(small.getdata())
mean = sum(pixels) / len(pixels)
bits = [1 if p > mean else 0 for p in pixels]
return int("".join(str(b) for b in bits), 2)
That's the whole thing. One integer that represents the visual signature of a frame. It fits in a standard database integer column, computes in under a millisecond, and works on pretty much any visual input regardless of what made it. In the retro game context, this means the agent can use it to recognize "I've been in this room before" purely from the screenshot - no game-specific instrumentation or fancy RAM mapping techniques required. When I first tested it I kept waiting for the catch. There isn't really one - it just works for this use case pretty well!
Hamming distance: fuzzy recall
Storing a hash is easy. The interesting part is matching 'em - given the current frame's hash, find the closest hash in memory and decide whether they do, in fact, likely represent the same location.
This is where Hamming distance comes in. The Hamming distance between two binary numbers is the count of bit positions where they differ. You compute it with something like this:
def hamming_distance(hash1: int, hash2: int) -> int:
return bin(hash1 ^ hash2).count("1")
Two identical frames will produce a distance of 0. Two completely unrelated frames will typically land around 32 or so (half the bits differ by chance). The question is where you draw the line between "same room, minor variation" and "genuinely different location."
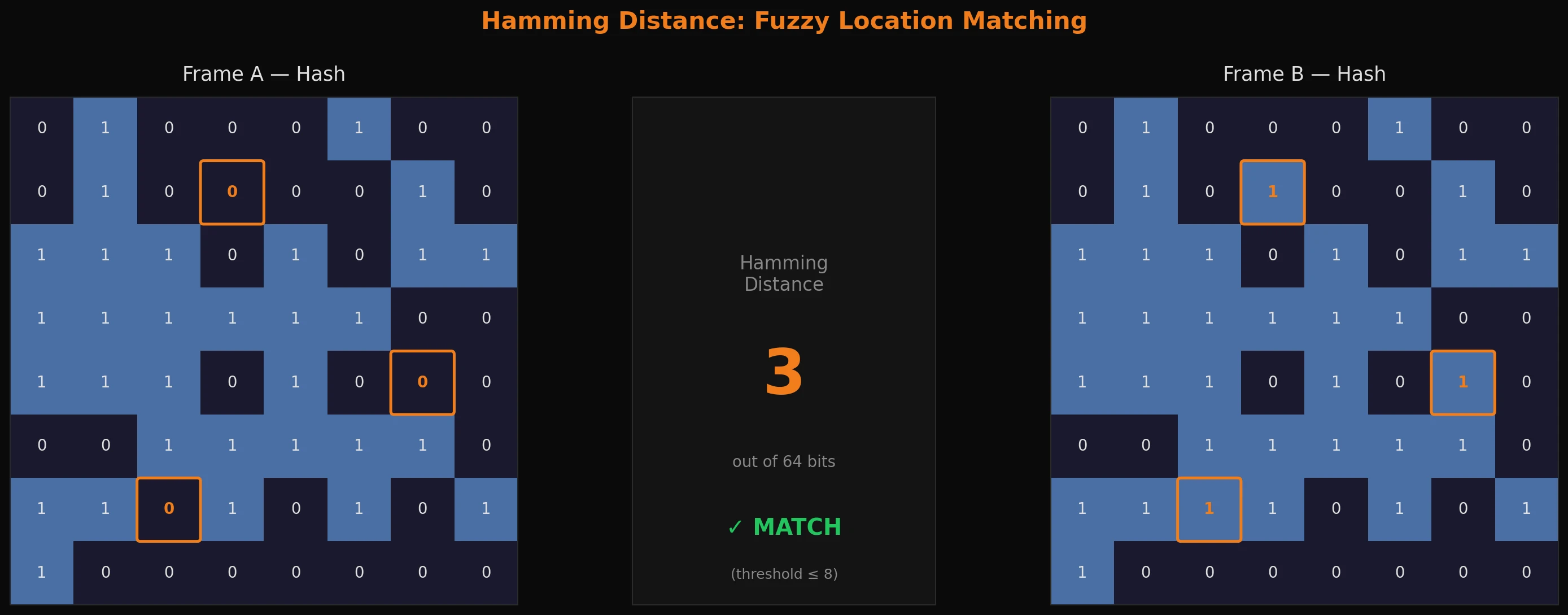
We settled on 8 bits - or around 12.5% of the 64-bit hash - and it holds up so far relatively well in practice:
- A character sprite mid-animation: ~1-2 bits different. Match.
- A blinking cursor or minor palette shift: ~3-5 bits different. Match.
- A different room with a similar color palette: ~15-25 bits different. No match.
- A completely different scene: maybe ~28-35 bits different. No match.
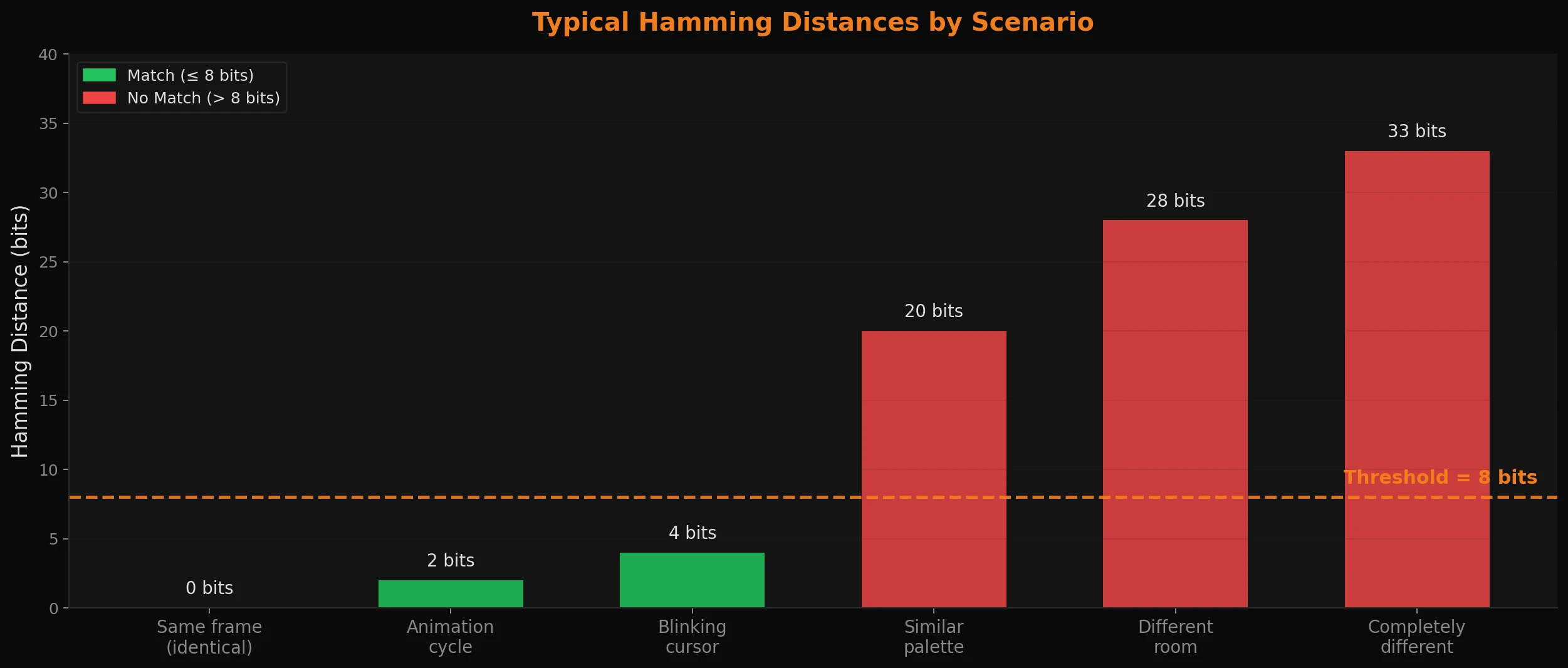
The right threshold depends on your environment. More visually noisy environments (water effects, screen animations, etc.) may need a tighter threshold; more static ones can afford a looser one. But 8 bits is a reasonable starting point and is easy to tune - you can just log the distances you're seeing and dial it in from there.
In practice, the lookup is two-phase: try to do an exact match first (faster), then scan for anything within the threshold (handles a little visual variation). The exact match covers the majority of cases.
What to remember
Once you can recognize a location, you need to decide what to store about it. At minimum, store what the agent observed there, what actions it tried, and which ones actually did anything.
{
"hash": 0x1a2b3c4d5e6f7a8b,
"description": "indoor room, exit to the north and east",
"successful_actions": {"NORTH": 3, "EAST": 1},
"failed_actions": {"SOUTH": 2, "WEST": 4},
"visit_count": 7
}
Figuring out whether an action succeeded is straightforward: compare the hash of the frame before the action to the hash after. If the Hamming distance between them exceeds your threshold, the screen changed significantly - the agent moved somewhere new, or something meaningful happened. If the hashes are still close, nothing changed - it walked into a wall, tried a locked door, pressed a button that did nothing, or something like that.
hash_before = get_current_hash()
execute_action("NORTH")
hash_after = get_current_hash()
if hamming_distance(hash_before, hash_after) > 8:
memory.record_success(hash_before, action="NORTH", leads_to=hash_after)
else:
memory.record_failure(hash_before, action="NORTH")
This is what is known as a binary reward signal - something the agent can act on with no training, no reward function, and no model updates required. Over time, if it's working correctly, the agent builds up a map of what works and what doesn't at every location it has visited. The next time it ends up in that same room, it already knows that going NORTH works and going WEST is a wall. It stops rediscovering the same dead ends over and over.
Decay: because the world changes
Here's the problem with storing failed actions: the world isn't static. In a game, a door that was locked early on might be unlocked after a certain event. If the agent permanently avoids any action it has ever failed at, it will get stuck the moment the environment changes - which in most games it absolutely will.
The fix is decay - and yes, we're intentionally building in a form of forgetting. Here we use it to reduce the influence of failed actions over time, weighted by how recently they occurred:
def get_action_weight(failure_count: int, frames_since_failure: int, decay_window: int = 500) -> float:
decay = max(0.1, 1.0 - (frames_since_failure / decay_window))
return failure_count * decay
A failure from 500 frames ago carries only 10% of the weight of a recent one. The agent stays cautious about things that recently didn't work while staying open to retrying things it failed at a long time ago.
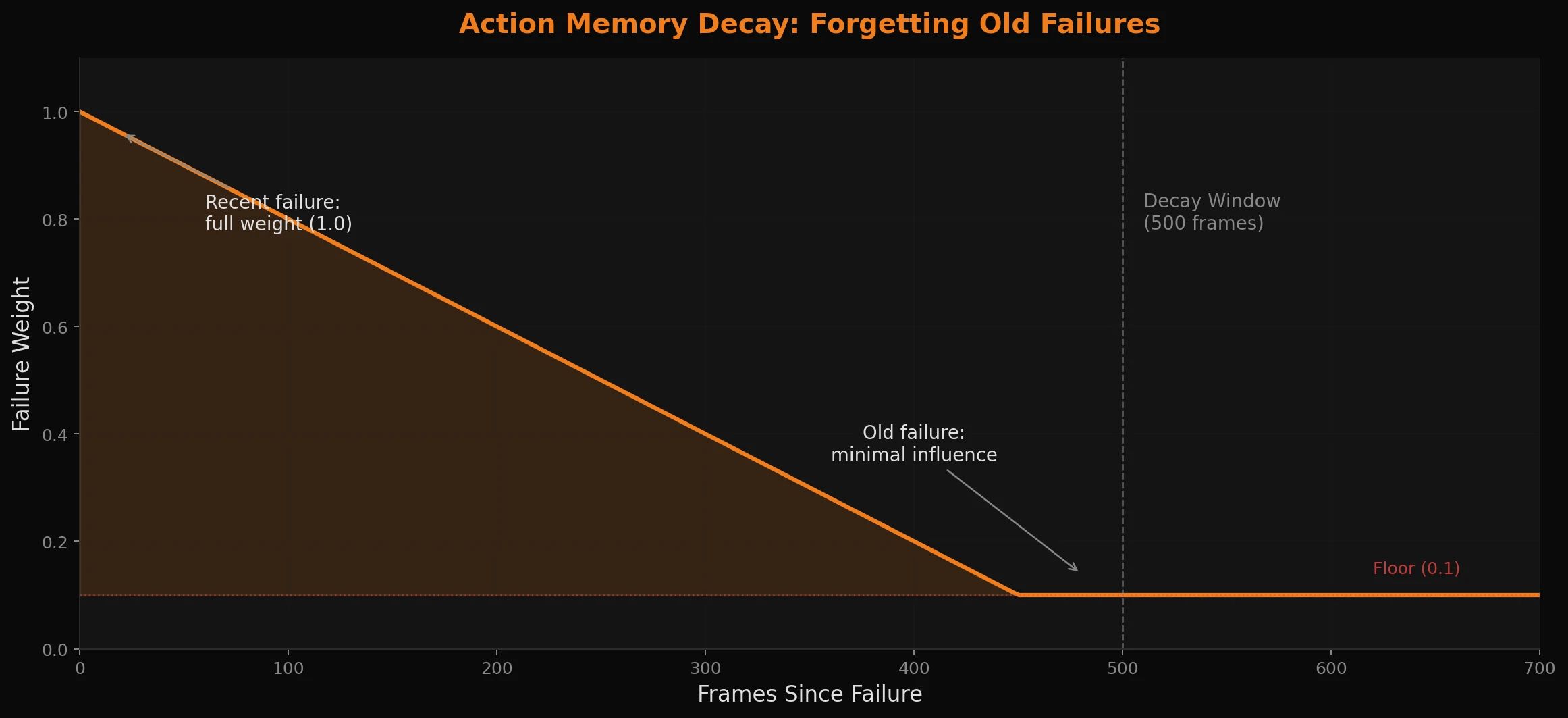
It's a simple idea, but it handles a surprising range of situations without any model updates or special-case logic. That locked door from the beginning of the game? Eventually the agent will try it again - and this time it'll open. It might take a while, but it's a lot faster than pure randomness. Way faster than monkeys typing on typewriters, at least. There's probably a relevant xkcd comic that fits the bill here, but I'm too lazy right now to find it.
Making the memory useful
Spatial memory is only valuable if the planning system actually uses it - otherwise you've just built a very organized and boring diary that nobody reads.
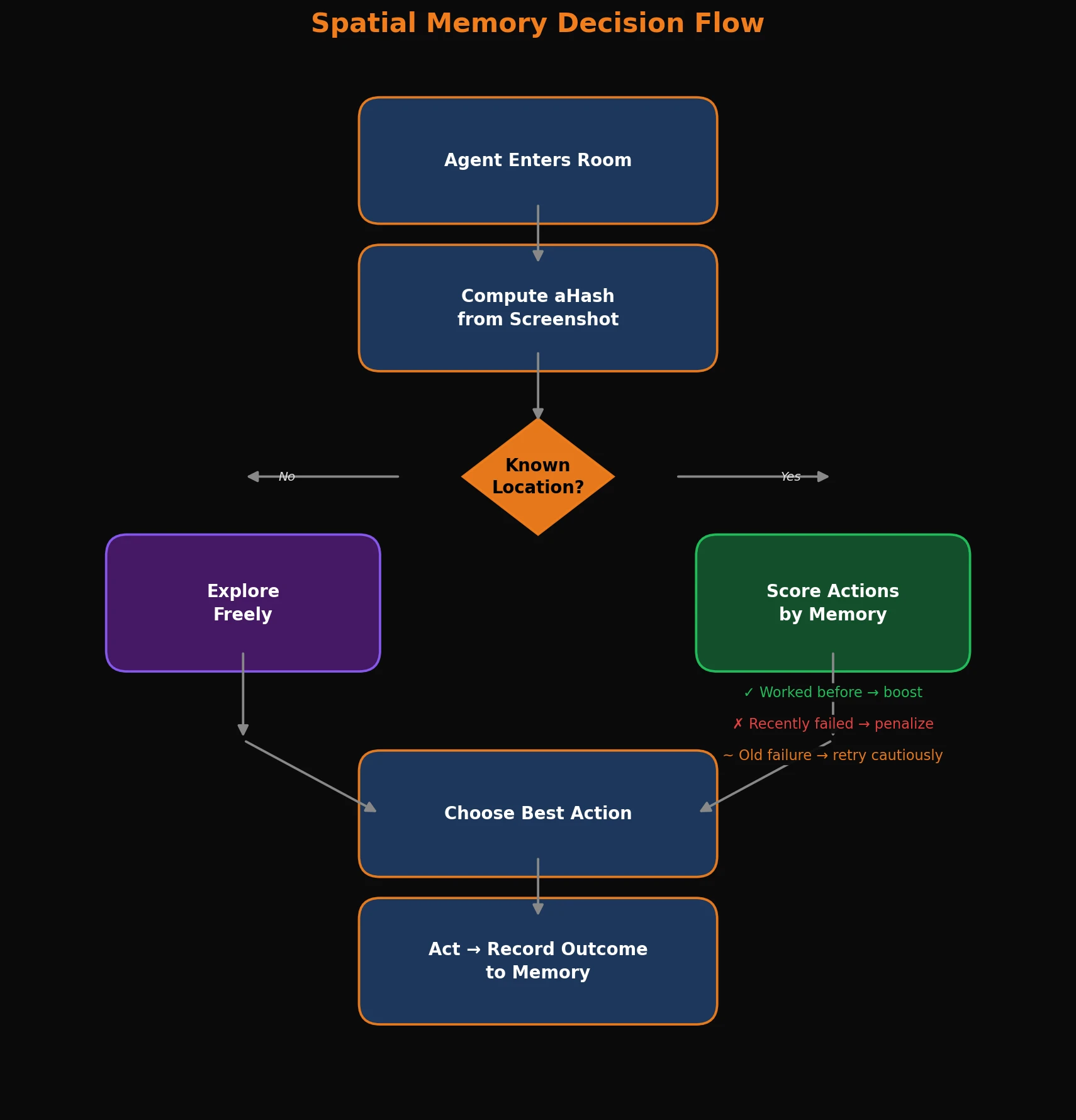
When the agent needs to decide what to do next, it queries location memory for the current hash and uses it to score its options. Actions that have worked here before get a boost. Actions that recently failed get penalized. And if it's been banging its head against the same wall repeatedly, the memory gets surfaced explicitly so the agent knows to actually try something different for once.
The result is an agent that, on returning to a familiar room, already has a feel for what's worth trying and what isn't - without having to relearn any of it. And because the memory persists to disk, what it figured out in one session is still there in the next. It genuinely gets better at navigating the same environment over time. Which, when you've watched an agent walk into the same wall forty times in a row, feels like a small miracle.
The same tool, a different question
Once you have perceptual hashing in place, you start finding other uses for it. One that surprised us a little: it's also the right tool for deciding when the agent should observe at all.
In a game environment, actions have visual consequences - an animation plays, a room transition happens, a dialogue box opens. You don't want the agent acting mid-animation. It'll get a garbage observation and make a bad decision based on a frame that doesn't represent any stable state. You probably want to wait for the screen to settle first to make sure you grab a good screen state that represents the actual visual information and ideas the AI should be evaluating. A picture is worth a thousand words, and the wrong picture is worth, in this case, a lot of wasted tokens!
The naive approach to this issue is adding a fixed delay: wait 500ms after every action, then observe. It works, but it's slow and wrong in both directions - too long for fast actions, too short for slow transitions. And what if a repetitive looping action in a game or the world state invalidates this timing anyway?
The better approach is to watch the frames coming in and wait for stability. If the current frame and the previous frame are perceptually similar enough, the screen has probably settled. If they're still changing by a large amount, probably keep waiting. We track this with a simple counter: increment it each frame that the hash has been stable, and reset it to zero when the hash changes. Once the counter hits a threshold (say, 10 consecutive stable frames, or so), it's potentially a good and safe time to observe visual state.
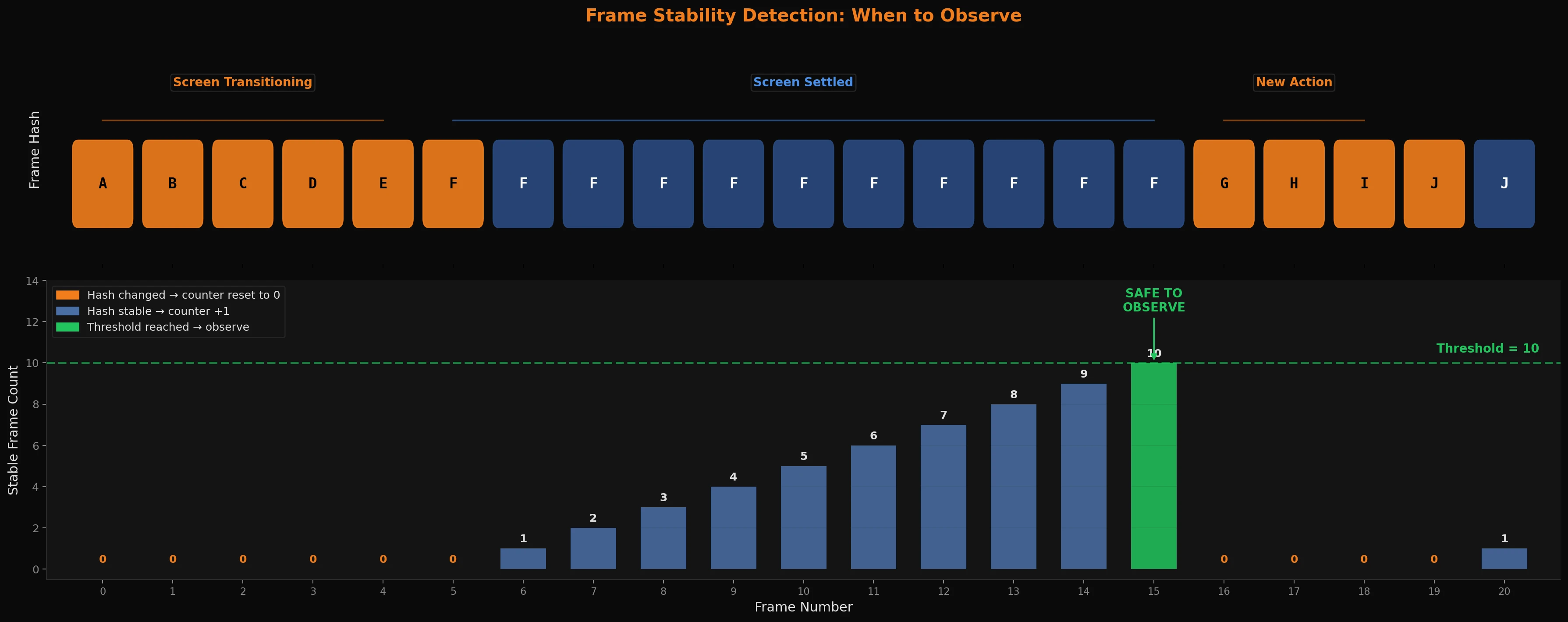
One optimization worth mentioning: most frames during a stable screen are identical - not just similar, literally the same pixels. So before doing any hash computation at all, you can do a near-instant checksum of a handful of sampled pixels. If those match, skip everything. Only when the checksum differs do you bother computing the full hash. In practice this means the expensive comparison almost never runs during stable periods, which can make a big difference when you're doing this on EVERY frame at 30 or especially 60fps.
The broader point is that perceptual hashing isn't a narrow solution to the location recognition problem - it's a general and more widely applicable way of asking "how similar are these two images?" and that question comes up in more places than you'd expect once you start building systems that operate on visual input.
What this actually gets you
The full system is three ideas stacked on top of each other. Perceptual hashing gives the agent a way to recognize locations from raw visual input with no environment-specific instrumentation. Hamming distance matching makes that recognition a bit resilient to the minor visual variance that's likely present in any real environment the agent is likely to see. Action memory with a decay that's been tuned correctly can turn each visit into a learning opportunity - the agent remembers what worked, what didn't, and stays open to the possibility that things have changed.
None of this requires a neural network or anything too fancy. None of it requires training data or a ton of additional compute. It's deterministic, easy to interpret, quick to implement, and fast enough to run in real time. The agent's spatial knowledge can live in a plain database you can open and read at any time, which is more than you can say for most ML-based approaches! It's kind of refreshing to have that amount of observability in data.
I want to be honest that this isn't a complete solution to agent memory - it's only one layer of it. Spatial memory answers "where am I and what have I tried here?" but any capable agent probably also needs some kind of short-term episodic memory (what just happened in the last few turns?), long-term semantic memory (what do I know about this world in general?), and/or a goal hierarchy that connects immediate actions to long-term objectives. Those are harder problems to tackle well, and they interact with each other in ways that aren't always obvious.
That's a topic for a future post soon - where we will go over a more complete memory architecture, how these different systems can work together, and how a goal hierarchy keeps an agent oriented across sessions that can run for hours while still making progress towards those long-horizon goals. After that, we'll get into something I find genuinely fascinating: memory compaction, knowledge crystallization, and how an agent can distill raw experience into structured, reusable knowledge rather than just accumulating a growing pile of observations and raw data.
More to come - We're just getting started!